Report
💡 Active projects and challenges as of 27.08.2025 18:55.
Hide text CSV Data Package Print
AI & LLMs
AI @ Hack4SocialGood
Draft / Working Paper
Introduction
In recent years, the use of Large Language Models (LLMs) has become increasingly popular at hackathons. These AI tools offer developers the ability to rapidly prototype and build intelligent applications, providing a competitive edge in fast-paced, time-sensitive environments. In this introduction, we will discuss the benefits of using LLMs at hackathons, provide an overview of alternative technical solutions, and address the data protection risks associated with using such tools.
Goals
The primary benefit of using AI at hackathons is the acceleration of the development process. By leveraging pre-trained models and APIs, developers can quickly incorporate advanced functionality into their applications without having to spend significant time and resources on training their own models. This enables teams to focus on solving the core problem at hand and delivering a more polished product within the limited timeframe of a hackathon.
Additionally, LLMs can help level the playing field for participants with varying levels of expertise. Teams with limited experience in natural language processing can still leverage the power of AI by incorporating pre-built models into their projects, while more experienced developers can build upon these models to create more advanced solutions. Conversational interfaces make it particularly quick and easy to get started.
Technical alternatives
While LLMs like OpenAI's GPT-4 offer a quick and easy way to incorporate natural language processing into hackathon projects, there are alternative technical solutions available. One such alternative is to train custom models using frameworks like TensorFlow or PyTorch. This approach requires more time and resources but allows for greater control over the model's architecture and training process, potentially resulting in better performance on specific tasks.
Another alternative is to use open-source pre-trained models, which can be fine-tuned for specific tasks using transfer learning. This approach combines the benefits of pre-built models with the flexibility of custom training, allowing developers to tailor the model to their specific needs without starting from scratch. You can find many of these in a public model registry such as https://huggingface.co/models or https://replicate.com/explore
Data protection risks
As with any technology that involves the processing of data, there are potential data protection risks associated with using LLMs at hackathons. Participants should be aware of the privacy implications of using third-party LLM services and ensure that they have obtained the necessary consent and level of due dilligence.
It is crucial to consider the security of the data being processed by LLMs. Hackathon organizers should establish clear guidelines for data handling and storage, and participants should take appropriate measures to protect sensitive information. This may include encrypting data at rest and in transit, implementing access controls, and regularly monitoring for potential security breaches.
Presenting your work
When presenting and making public your work based on AI models, it is essential to consider the following best practices to ensure that your work is accessible, understandable, and engaging to a broad audience:
-
Clearly explain the problem you are addressing: Begin by providing context and describing the problem or challenge that your work aims to address. This will help your audience understand the significance of your research and how it fits into the broader field of AI and natural language processing.
-
Introduce the model: Provide an overview of the model (e.g. LLM) as well as the techniques you used to train or refine it (e.g. RAG - Retrieval Augmented Generation), you used in your project, including its architecture, training process, and any pre-processing or post-processing steps you took. Be sure to highlight any unique aspects of your model or approach that set it apart from other similar models.
-
Describe your dataset(s): Discuss each dataset you used for training, fine-tuning, or evaluating your model. Provide details about its size, composition, and any relevant pre-processing steps. If you used a publicly available dataset, be sure to include a citation and a link for others to access it.
-
Highlight your results and findings: Share the results of your experiments, including any quantitative metrics (e.g., accuracy, perplexity, or BLEU score) and qualitative examples (e.g., generated text or summaries). Be sure to discuss the strengths and limitations of your model and any insights you gained from your research.
-
Discuss potential applications and future work: Consider the potential applications of your work and how it might be used to solve real-world problems. Additionally, outline any planned or potential future work, such as further experimentation with different model architectures or datasets, or the development of more advanced systems.
-
Make your code and models available: To promote transparency and reproducibility, make your code and trained models publicly available on platforms like GitHub or Hugging Face. This will allow others to build upon your work and contribute to the broader AI community.
-
Share your work through multiple channels: To maximize the visibility and impact of your research, share your work through various channels, such as academic conferences, workshops, and journals, as well as social media platforms, blogs, and online forums.
By following these best practices, you can effectively present your work at Hack4SocialGood, contributing to the ongoing advancement of AI and natural language processing technologies in the social work sector.
Please contact our team if you have any questions!
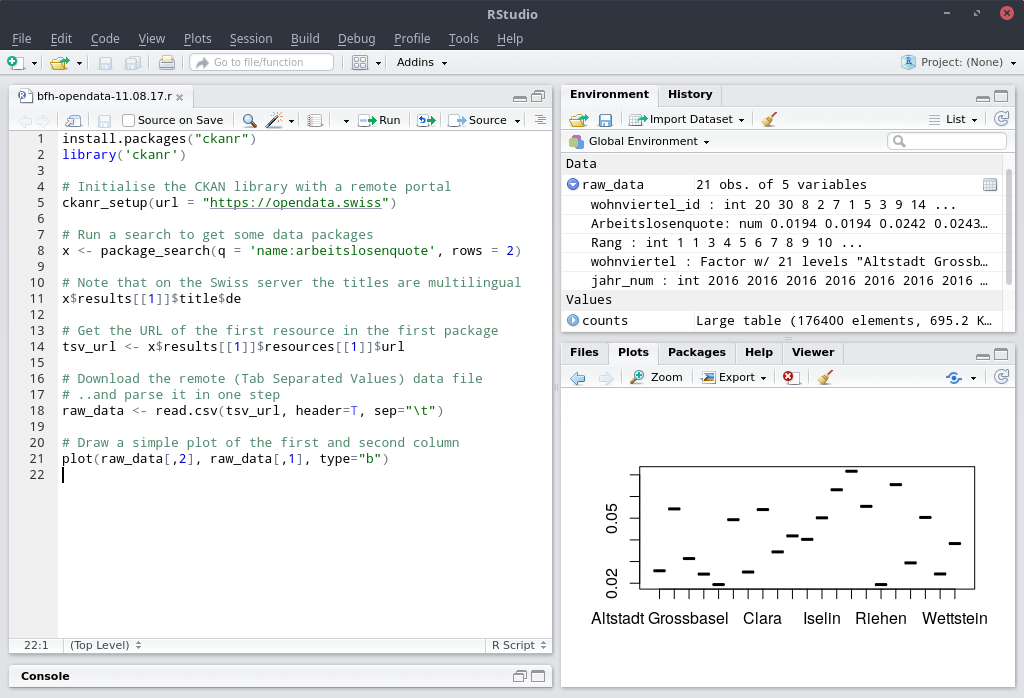
CKANR
Accessing open data with style
The image above is a screenshot of an example R program running on RStudio Cloud. This uses the R library for CKAN to connect to opendata.swiss, data.stadt-zuerich.ch and other data portals which support the CKAN API. Why is this important?
- You are using the latest version of the dataset;
- Your program is showing each step of the data extraction process;
- If there are notable changes to the data, including errors or improvements, they will soon be picked up;
- Additional metadata that is not part of the dataset content can be useful to your process.
Try copying and adapting the code for yourself:
library('ckanr')
# Initialise the CKAN library with a remote portal
ckanr_setup(url = "https://data.stadt-zuerich.ch/")
# Run a search to get a list of datasets
datasearch <- package_search(q = 'frauen', rows=20)$results
# Take the first result available
opendataset = datasearch[[1]]
print(opendataset$title)
print(opendataset$resources[[1]]$name)
# Get the dataset contents through the first resource URL
csv_url = opendataset$resources[[1]]$url
# Read as CSV for further processing, visualisation..
csvdata <- read.csv(csv_url, header=T, sep=",")
Datahub Cloud
Publish datasets and data stories using markdown with a few clicks.
As a special support of Hack4SocialGood 2024, a member of the Datopian team will be available to contact for assistance with this brand new product, which we hope will help your hackathon project shine!
How it works
Using DataHub you can easily mix rich text content with data and data visualizations. No need to code or embed your charts and tables: they can be added to the document with a very simple syntax, either by passing inline data or simply referencing your data files. What you end up with is a plain text, human-readable document enriched with data visualizations, that is simple to edit and looks awesome when published with DataHub.
Publish your hackathon dataset or data-driven story with Datahub Cloud
Sharing anything from hackathon explorations to the results of a scientific study with open standards can really pay off in terms of longevity, reach, and remixing. At Hack4SocialGood, we can introduce you to the latest tools for publishing open data, and give you feedback on improving the quality and reliability of your entire data lifecycle.
Join the Hackathon and get access
Visit datahub.io to join the Waiting List - or come to Hack4SocialGood and get access and live support from the Datopian team!
How to create data-rich stories with a few clicks:
- Choose your Repo
Create or update some markdown files and push them to GitHub. You can create a new GitHub repository or use an existing one. Here is an example bit of Markdown that shows how to add some basic metadata to your story:
---
title: My Data-Rich Blog Post
authors: [Jane Doe]
date: "2023-11-30"
---
## Welcome to My First Data-Rich Blog Post
This is my first blog post. I'm so excited to try publishing it with DataHub!
- Add visuals
Enhance your content with some data visualizations. Easily add line charts, tables, maps, and more directly into your content. For instance, you can add a simple linechart like this:
<LineChart
data={[
["1850", -0.41765878],
["1851", -0.2333498],
["1852", -0.22939907],
["1853", -0.27035445],
["1854", -0.29163003],
]}
/>
- Publish & share
Push to GitHub, then use DataHub Cloud to bring your site to life instantly. Congrats, your repository is now a beautiful site that keeps your audience captivated!

{kind=link}
Bugs, issues and suggestions re DataHub Cloud ☁️ and DataHub OpenSource 🌀
DataHub
This repo and issue tracker are for
- DataHub Cloud ☁️ - https://datahub.io/
- DataHub 🌀 - https://datahub.io/opensource
Issues
Found a bug: 👉 https://github.com/datopian/datahub/issues/new
Discussions
Got a suggestion, a question, want some support or just want to shoot the breeze 🙂
Head to the discussion forum: 👉 https://github.com/datopian/datahub/discussions
Chat on Discord
If you would prefer to get help via live chat check out our discord 👉
Docs
DataHub OpenSource 🌀
DataHub 🌀 is a platform for rapidly creating rich data portal and publishing systems using a modern frontend approach. Datahub can be used to publish a single dataset or build a full-scale data catalog/portal.
DataHub is built in JavaScript and React on top of the popular Next.js framework. DataHub assumes a "decoupled" approach where the frontend is a separate service from the backend and interacts with backend(s) via an API. It can be used with any backend and has out of the box support for CKAN, GitHub, Frictionless Data Packages and more.
Features
- 🗺️ Unified sites: present data and content in one seamless site, pulling datasets from a DMS (e.g. CKAN) and content from a CMS (e.g. Wordpress) with a common internal API.
- 👩💻 Developer friendly: built with familiar frontend tech (JavaScript, React, Next.js).
- 🔋 Batteries included: full set of portal components out of the box e.g. catalog search, dataset showcase, blog, etc.
- 🎨 Easy to theme and customize: installable themes, use standard CSS and React+CSS tooling. Add new routes quickly.
- 🧱 Extensible: quickly extend and develop/import your own React components
- 📝 Well documented: full set of documentation plus the documentation of Next.js.
For developers
- 🏗 Build with modern, familiar frontend tech such as JavaScript and React.
- 🚀 Next.js framework: so everything in Next.js for free: Server Side Rendering, Static Site Generation, huge number of examples and integrations, etc.
- Server Side Rendering (SSR) => Unlimited number of pages, SEO and more whilst still using React.
- Static Site Generation (SSG) => Ultra-simple deployment, great performance, great lighthouse scores and more (good for small sites)
Data Packaging
From Dataset to Frictionless Data
Once you have identified Open Data of relevance to your project, and made use of it inside of your project, you can publish it within a container that allows easy and up-to-date use from a range of programming languages (Python, R, Julia, JavaScript, etc.) and tools (Dribdat, Dataworld, Superset, PowerBI, etc.)
Here are example instructions for use within the R language:
https://bd.hack4socialgood.ch/project/54
If your data is not Open, or needs to be protected in some way, a Data Package which contains only the metadata can still be very useful to people who would like to contact you for more information about your research. They would be able to see a schema, or even a sample of the data, in a convenient and standard way.
How to create a Data Package
🌊 The source of the sample data in this guide is opendata.swiss.
(1) Create a tabular dataset
Download a spreadsheet (e.g. get a copy of the data shown above), and convert the worksheet containing the data to a CSV file. Preview:
(2) Generate a Data Package
Use the Data Package Creator to upload your CSV file (click Load at the top right), then Add Fields to show all the columns. Check the various field settings, add metadata (name, title, license, etc.) on the left hand column, and finally Validate and Download your Data Package.
 📦 Frictionless Data: datapackage.json
📦 Frictionless Data: datapackage.json
You can also Upload the example shown above into the Creator tool.
(3) Next steps
To find out how to publish the Data Package in such a way that it is accessible to a general audience, visit the Software Toolkit page of the Frictionless Data project. For example, uploading to Datahub.io allows the use of VEGA visualizations and embedded maps.
🗺️ Map: [map.geo.admin.ch](https://map.geo.admin.ch/?lang=de&topic=ech&bgLayer=voidLayer&layers=ch.swisstopo.swisstlm3d-karte-farbe,ch.bafu.gewaesserschutz-badewasserqualitaet,ch.bafu.hydrologie-wassertemperaturmessstationen,ch.meteoschweiz.messwerte-lufttemperatur-10min&E=2601495.27&N=1201237.93&zoom=4&layers_opacity=0.8,1,1,1)Compare this to the GeoAdmin map of the data above, as well as the Opendata.swiss "Preview" tool shown at the top of the page, which depends on user interaction.
No Code
Grosse Wünsche, kleines Budget? Neue Möglichkeiten dank No-Code
Keynote von David Brühlmeier, Leiter IT bei sozialinfo.ch
Links
- No-Code Tools: nocode.tech
- Bubble bubble.io
Bubble-Beispiele aus der Schweiz
- Ein Online-Shop für Autos: Fairie
- Yatzy
- Digitalcheck von Sozialinfo digitalcheck.sozialinfo.ch
Web Scraping
We discussed the question of collecting data through scraping of Web sites, PDF files and APIs in class, but did not manage to get too deep into specifics. On this page are recommended tutorials. Feel free to add a comment if you have another one in mind!
Web pages
- Introduction to Web scraping in R from University of Wisconsin-Madison
- Scrapingbee - Web Scraping with R
- RStudio - rvest: easy web scraping
PDFs
APIs
- https://www.dataquest.io/blog/r-api-tutorial/
- https://jeroen.cran.dev/jsonlite/articles/json-apis.html
- https://www.r-bloggers.com/2015/11/accessing-apis-from-r-and-a-little-r-programming/